
Beyond browsing and searching: Design and development of a platform for supporting curatorial research and content creation
Leonardo M. De Araújo, Universität Bremen, Germany, Michael Lund, University of Bremen, Digital Media in Education, Germany, Tossawat Mokdara, King Mongkut's University of Technology Thonburi, Thailand, Heidi Schelhowe, Universität Bremen, Germany
Abstract
Many cultural institutions (CIs) have redefined their role in society in order to become meaningful for their communities. Particularly in museums, conversations around artifacts hold the potential to enhance interpretation and provoke the production of meaningful insights. However, there are challenges when institutions grant visitors permission to contribute. One of the main problems concerns the lack of strategies to profit from visitors’ insights. Museum kiosks are usually for browsing and searching, and popular social-media websites do not offer ways to store, analyze, and build upon the content produced on those environments. This paper presents the conceptual and technical designs of an experimental platform aimed at assisting interpretation and generating content. The platform, currently in the prototype phase, will serve both institutions and affiliated communities by attempting to improve the quality of outcomes in the context of CIs’ knowledge assets. The platform is based on two strategies: easy creation of structured data, and recommendations. Structured data can be used in combination with machine-learning algorithms in order to offer meaningful recommendations. In addition, curatorial research can also be assisted since the application provides an easy-to-use interface for organizing content through Knowledge Maps, which are used for feeding the recommendation system with content from other museum professionals and visitors' insights.Keywords: curatorial research, content production, linked data, collective intelligence, museum kiosk, machine learning
1. Introduction
Our previous research (De Araújo, 2014) focused on constructing a theoretical model for a technological artifact able to open channels between cultural institutions (CIs) and their communities. A successful model would be capable of promoting a constant conversation among the main involved actors. More specifically, our initial interest was to give greater voice to the communities allowing interpretation processes to occur with the help of technology.
CIs are under pressure to make the transition from static providers of content to flexible facilitators capable of engaging with their audiences. In this scenario, visitors’ contributions are especially desirable. Visitors’ insights can not only be beneficial to their own understanding of collections, but also offer important inspirations for institutions. There are many practices for promoting conversations between communities and institutions. Inquiry-based teaching methods, for example, offer good strategies for both developing critical thinking and facilitating insights. Those strategies also provide visitors with the opportunity to produce content that tells stories about objects. However, those practices are usually designed for presential meetings and small groups.
In this sense, technology can play an important role in trying to expand those technics to broader audiences. However, there are challenges involved when using technology. Especially through social media, several attempts in trying to engage visitors culminate in problems ranging from deviating outcomes to absence of engagement. Intentions of the institution to promote some contributions by adding them to their knowledge assets are then interrupted. Therefore, a model especially adapted to CIs’ contexts is needed.
In order to understand how technology can benefit CIs in dealing with complexity and supporting content production, we analyzed successful models in computer science that were able to catalyze interaction inside communities to produce remarkable results. In addition, we tried to understand what is behind some highly engaging social-media strategies that are effective in producing relevant user-generated content. We also highlighted some principles that provide scaffolding for creative processes, which are important for content creation. Finally, we contextualized out findings in regard to CIs’ contexts before presenting the concept of the Lisa Platform, which tries to incorporate the main lessons learned.
2. Theoretical background
We have examined three models that effectively harnessed the collective intelligence present in their gravitating communities: Software Platforms, the Open-Source Movement, and Collaborative Systems.
Software Platforms inherit all the characteristics of platforms in general, which are structuring foundations where a set of independent elements and interfaces can be arranged, rearranged, and innovated upon (Griffiths, 2010). In platforms, diversification and innovation can be achieved by combining, resetting, and extending capabilities of shared key components (Baldwin & Woodard, 2009). Highly modularized systems optimized for reuse and sharing of components can lower costs and simplify production processes, enabling fast prototyping to occur. Concepts such as modularization and reuse are critical to create rich ecosystems, such as the Open-Source Movement.
On one hand, the Open-Source Movement has its technological foundations in the capabilities afforded by platforms. On the other hand, it is a well-known example of collaborative thinking capable of producing high-quality outcomes. This movement focuses primarily on considering its members as codevelopers. In addition, because of its licenses, the Open-Source model promotes the production of new knowledge based on other people’s previous works. No one needs to reinvent the wheel. The community is also very motivated. As Weber (2000) points out, members engage in projects not seeking monetary rewards, but for individual reasons, such as contributing to socially relevant projects, gaining visibility, learning new skills, or just for fun.
Collaborative Systems mix both models. On one hand, they need a fundamental set of key elements to enable communication and sharing of knowledge. On the other hand, they enable collaborative content production. Bafoutsou and Mentzas (2002) and Moreno-Llorena et al. (2013) propose different categories of collaborative systems according to their functionalities. For our project, we analyzed Group File and Document Handling (GFDH) Tools, since significant cases belong to this category, such as Wikipedia. In addition, we explored the Online Social Network Systems (OSNS) Tools, by virtue of their powerful influences in changing paradigms. Finally, we also considered Electronic Workspace (EW) Tools, as few of them were able to incorporate creative practices inside their environments.
2.1 GFDH tools: The Wikipedia case
GFDH Tools support the management of documents that are handled by groups. It includes shared-view, synchronous or asynchronous editing, and notification mechanisms (Bafoutsou & Mentzas, 2002). With more than 22,000,000 articles in 285 languages (Wikipedia, 2015), Wikipedia is a good example of a GFDH Tool. The importance of Wikipedia today is beyond question; so is the quality of the articles there produced. The high volume of contributions that Wikipedia receives daily gives this platform its strength. This is only possible due to Wikipedia’s un-elitist approval procedure, when compared to its predecessor Nupedia. In addition, Wikipedia considers everything a “draft in progress, open to revision” (Rettberg, 2005). For knowledge production in the digital age, this model is suitable because it is flexible enough to adapt itself quickly to new facts and interpretations. New knowledge is created also based on other people’s previous work. A clear set of rules is crucial to organize the content that is constantly being produced.
2.2 OSNS tools: Relevance of other collaborative system models
When thinking about participation, collaboration, and community engagement through technology, social media and their highly contagious (Kramera, Guillory, & Hancock, 2014) effects are the choice of the majority of CIs. From the ten most attended museums around the world (Toby, 2014), all of their websites offer users the option to follow on Facebook, and the majority have Twitter channels. The following paragraphs point out features of those social networks that allow flexible organization of content, distribution, and relevance.
2.2.1 Metadata and Linked Data
From hashtags to “like” buttons, the core of almost all of these features is the aggregation of metadata around raw information in order to describe and instruct how the computer should handle it. Metadata also plays an important role concerning the relationships among resources. Previously, computer models were based on rigid hierarchical formats. This was a limiting factor for data manipulation and analysis. When Tim Berners-Lee wrote his proposal for the Web (Berners-Lee, 1989), his main concern was to establish a more flexible and effective way to store, link, and retrieve data that could cope with complexity. He suggested that fixed hierarchical systems were not up to the task, and that a web of annotations would appear as a better model. The Web offered a better paradigm to deal with large data sets. Now, in order to cope with even greater complexity, the Web relies on extra layers of metadata that expand meaning. The social Web is able to effectively handle information and maintain high degrees of identification and addressability.
As distribution and horizontality deepens, so does the process of democratizing the Web. In fact, the relevance of metadata generated from ordinary individuals is higher than ever. Not only webmasters, but also Google’s old PageRank algorithm (Page at al., 1999) lost importance as means for creating and measuring importance of content. Ratings, shares, and comments are more effective as metrics for determining popularity.
In Facebook’s model, for example, social features are all supported by its Graph API, which is derived from the idea of a social graph. The model is a representation of how the information on Facebook is composed. It has three main entities: (1) nodes: representing things, such as a user, a comment, etc.; (2) edges: representing relationships between nodes; and (3) fields: representing properties, which are additional information for nodes and relationships (Facebook Developers, 2014).
The concept of trying to organize Web content through nodes, relationships, and properties originated from developments in the fields of Semantic Web and Linked Data. Both provide a framework for common data formats and relationships that aim at making information on the Web meaningful to computers. By allowing automated reasoning, the computer is able to understand terms “more effectively in ways that are useful and meaningful to the human user” (Berners-Lee et al., 2001). The more structured data that is made available, the more relevant and accurate responses the computer is able to generate, especially when integrated with artificial intelligence algorithms.
2.2.2 Graphs and thoughts
One of the goals of Linked Data is to provide a graph-based data model to describe things in the world. It encodes data in triples, which are structures in the form of subject–predicate–object (Bizer, Heath, & Berners-Lee, 2009). Facebook uses a similar structure that is also based on triples. When the user presses the Like Button, for example, a relationship is then established between two entities. This simple format enables both users to write queries that resemble natural language and computers to respond intelligently to them.
Graphs are not only powerful structures to represent social relationships or relationships among data on the Web, but also good models to depict how the brain and our thought processes are structured. The scientific community (Adamic, 1999; Bassett & Bullmore, 2006; Watts & Strogatz, 1998; Eguiluz et al., 2005; Marupaka, Iyer, & Minai, 2012) has already demonstrated that small-world graph topologies are common patterns of complex network systems found in nature and technology. According to Bassett et al. (2006), this is also “an attractive model for the organization of brain anatomical and functional networks because a small-world topology can support both segregated/specialized and distributed/integrated information processing.” In fact, small-world network models have even been suggested as structures that are behind functional processes such as insights and creativity in individuals (Schilling, 2014).
Small-world graph models represent not only how social networks operate, but also how our brain and its processes function. Likewise, they are models for creative insights. Beside a few question-and-answer websites (e.g., StackExchange (http://stackexchange.com/), Quora (https://www.quora.com/), and ResearchGate (https://www.researchgate.net/)), not many OSNS Tools try to take advantage of powerful graph structures to the production of creative knowledge done collaboratively. For non-computer scientists or non-engineers, harnessing the power of Linked Data can be challenging, since the implementation of those concepts expects technical skills and understanding of how they work. Even more challenging is to decontextualize those technologies in order to tackle different and specific problems, such as modifying their purpose from machine to human enhancers.
2.3 EW Tools: Translating processes into software to support complex work
EW Tools provide groups with virtual working spaces where several annotations, documents, and files can be centrally stored (Bafoutsou & Mentzas, 2002). In addition, those platforms can support to-do lists, calendars, address books, and virtual environments for specific projects. Many educational online platforms (e.g., MOOCs) are based on this model. Moreover, few EW Tools are specifically designed for creative production. They range from a simple collaborative noticeboard maker (e.g., Padlet (http://padlet.com/) and Trello (https://trello.com/)) to social mind-mapping apps (e.g., Popplet (http://popplet.com/) and Idea Sketch (http://www.nosleep.net/)). More advanced collaborative workspaces for creative production try to incorporate a more comprehensive set of methodologies for creative production into their architecture. One of those tools is the application Batterii (http://batterii.com/), which provides supports and makes explicit some of the phases of the design thinking creative process (Brown 2009), such as collaborative gathering of inspirations, deriving insights from previous research, and lately generating more concrete ideas from those insights.
2.4 Guidelines
Table 1 presents an overview of the main lessons learned. We propose these features as necessary for systems designed for harnessing the collective intelligence of communities, organizing information, producing relevance, and engaging individuals. Computer applications that incorporate those features hold the potential to deal with content produced by a considerable number of individuals, and yet organize information in a meaningful way. The first three columns point to where those features were originated, considering the three computer science models discussed in this paper: Platforms (PL), Open-Source (OS), and Collaborative Systems (CS). The two last columns indicate whether the feature in question helps to support generation of knowledge (KS), organize social groups (SO), or both.

Table 1: guidelines for designing applications that support content production with acceptable quality
3. The Lisa Platform
The Lisa Platform is an attempt to materialize the most important concepts analyzed above. Lisa is a collaborative graph-based platform that provides scaffolding for content creation, by taking advantage of Linked Data technics to provide meaningful recommendations. The platform is divided into two different modules, both aiming initially at curators and researchers. The first module provides the means to gather, categorize, connect, and store information into particular graph structures, here called Knowledge Maps. It also provides both visualization of structured data and lists that can be easily searched. The retrieval of information in this module has the purpose of aiding the creation of relationships among data previously stored, therefore creating a comprehensive mapping of collections and information about them. The second module supports content production by providing meaningful recommendations based on the Knowledge Maps. Recommendations are originated from both graph structures and Machine Learning algorithms. Adaptations for public spaces of the Knowledge Maps can also provide visitors with interesting information about relationships between objects, revealing stories behind exhibitions. In addition, visitors can add their own insights and opinions about the collections. Those insights enrich the Knowledge Maps, further improving the recommendations in a cyclical process.
3.1 Architecture
3.1.1 Module I
Instead of building an application from scratch, Module I (figure 1) was built as an extension for the Firefox browser (https://www.mozilla.org/) in order to take advantage of already built-in capabilities for dealing with a variety of different kinds of media. By using the resources already available from Mozilla, the plugin distribution is facilitated, since public repositories are accessible for all Firefox users. Below, we will present some of the main features of this module and discuss how the theoretical model is applied to this prototype.

Figure 1: interface of Module I
Metadata as an extra layer of meaning
One of the main strategies of Module I is to add an extra layer of information on top of preexisting resources in order to make information manageable (see table 1, G17). No technical skill is necessary to implement this strategy, because the user does not need to modify the document itself, but instead Lisa extracts information from it and creates a node pointing to the source. Extra layers of metadata can be then applied to the extracted information. Those entities are used to enable contextualized information retrieval.
Small-world graphs instead of hierarchical models of organization
Most of the advantages of using graphs were already discussed previously. Not only machine but also human analysis derived from graph visualizations can be rich sources of inspiration. Graph topologies can be easily translated into visuals. As stressed by design thinking methodologies, visuals can lead to the generation of insights that are essential for creative results (see table 1, G14). Although many design thinkers use mind maps as tools for creative thinking, better results can be achieved and greater complexity can be handled with less limited structures.
The main difference between Mind Maps and Knowledge Maps, for example, is that Knowledge Maps give great importance to relationships, providing extra and important meaning. In addition, mind maps are less flexible structures, because the relationships are usually hierarchical developments rigidly connected to their origin points. As O’Donnell et al. (2002) point out, Knowledge Maps can also “serve as scaffolds or supports to cognitive processing because they can reduce cognitive load, enhance representation of relationships among complex constructs, provide multiple retrieval paths for accessing knowledge, provide support for students whose verbal skills are weak, and serve as important props for communicating shared knowledge” (O’Donnell, Dansereau, & Hall, 2002) (see table 1, G5, G21, and G22).
In Lisa, users create a set of independent and therefore modularized Knowledge Maps (see table 1, G1) that can have their visibility set to either public or private. Moreover, users can take advantage of Knowledge Maps produced by other individuals and establish relationships with them, therefore making use of other peoples’ knowledge to derive new meaning and scale knowledge (see table 1, G3). Nodes can be easily modified, and the system encourages new relationships to be created every time new information is inserted (see table 1, G9).
Linked Data strategies

Figure 2: Knowledge Map about graphs
Inspired by Linked Data, our model is designed to represent mental connections usually performed during the research of a certain topic. Because of the Linked Data capabilities of the tool, the data of Knowledge Maps are available as structured data that can be made available by endpoints. Therefore, Module I does not impose any restriction on how the information will be visualized. In this sense, in addition to Module II, new modules can be attached to the platform and take advantage of the affordances it provides (see table 1, G2 and G4).
3.1.2 Module II
The goal of Module II is to support curators and researchers while creating digital content by providing meaningful recommendations. The recommendations are derived from: (1) keywords that are typed during the writing process, and (2) possible paths in the Knowledge Maps that have as reference both previous accepted recommendations and the most likely current node, which is calculated based on (1). For example, when creating a text, the module analyzes a limited set of recently typed keywords in order to define the most likely topic this new idea refers to. Based on that and past decisions done by the author, the module actively offers hints (a set of nearest nodes) that are connected to the topic (current node) found. Machine learning is used to suggest types of relationships that are inferred from the keywords (representing the new idea) and the recommended nodes. This module can bring real benefits for overall quality of the production because the Knowledge Hints are not restricted to personal maps, but the system considers all the most relevant possibilities from other members of the community (see table 1, G16). The insights created by visitors (see section 4, “Relevance of Lisa Platform for cultural institutions”) are also presented in this module as recommendations, since they also integrate the maps.
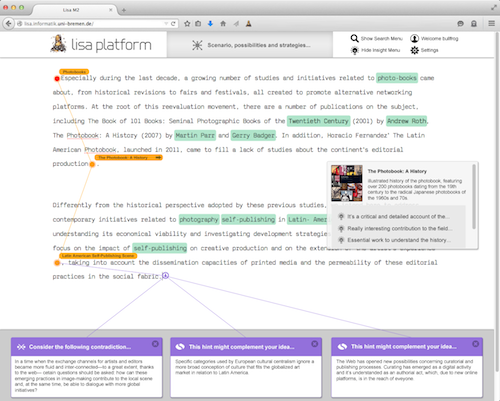
Figure 3: recommendations (in purple) given by relevant keywords and mental paths
One of the inspirations for this module was a scaffolding strategy used in many programming development environments called code hinting, which is a context-aware code completion feature that supports programmers by speeding up coding and reducing typo errors. It also offers quick-and-dirty help for remembering exact names of methods and classes. This strategy works well for code because, although creative, coding is restricted to limited group of well-defined recurrent commands. When trying to reproduce the same strategy in, for example, word processors, as text hinting, the results are usually frustrating for the user, since natural language is not as limited as code. Text hinting cannot offer much besides completion of most frequent words used in the text, because there is no comprehensive contextualized database to support more complex recommendations. Furthermore, most of the examples of those strategies, no matter if code hinting or text hinting, are indeed intrusive, in the sense that the hints appear right after the cursor trying to guess what the user wants to type next.
For an application to support production of content for CIs, such intrusive and limited methods are not suitable, because they do not add any real gain to the field. Hence the necessity of the Knowledge Maps created by professionals and audiences of institutions. Knowledge Maps are the fertile ground where the meaningful recommendations come from. Moreover, in order not to be intrusive, recommendations must disturb the interface as minimally as possible. Thus, instead of blocking the text area with hints, Module II will use the feed strategy, which provides users with frequent updates on the lower part of the interface. The user can subscribe to Knowledge Maps of certain individuals in order to receive updates in the form of either lists or small graphs. The recommendations are also planned to support different kinds of media.
4. Relevance of Lisa Platform for cultural institutions
4.1 General scenario: Curatorial research
In a first moment, the Lisa Platform is directed mainly to curators and researchers of CIs. The idea is to create an ecosystem where professionals use this tool for their own research, and by doing so they construct Knowledge Maps that provide valuable information about, for example, museum objects and meaningful relationships that connect them. Because Knowledge Maps are available in the cloud, they can be shared among other professionals who, for example, work in planning the same exhibition. In addition, they can be collectively enriched. When creating text for exhibitions or planning a possible storyline, relationships and mental paths are explicitly exposed during content creation. Because of that, the system presents the author with other information that, for example, contradicts the current topic, complements a certain idea, or explains a concept (see figure 3).

Figure 4: general scenario
As explained previously, the Lisa Platform offers services that make the data available in formats such as JSON or XML. Therefore, museum kiosks can take advantage of the Knowledge Maps created by curators. Depending on the concept of the kiosk, the Knowledge Maps can be used to highlight relationships among the several objects displayed. In addition, visitors can be invited to give their insights about particularities artifacts (see Table 1, G20). Those insights then enrich the Knowledge Maps created previously by curators and researchers, in a cyclical process (figure 4). Those insights hold the potential to, for example, enhance understanding of a topic (see Table 1, G23 and G24).
The Lisa Platform does not aim at consensus, but to incorporate mechanisms to deal with contradicting ideas. The modular architecture of the platform assures addressability and integrity of the maps. This is crucial when opening up this platform to the general public (see Table 1, G25), because ordinary individuals will be able to retrieve, manipulate, and add their contributions in a non-disruptive way, but yet integrated to the network.
4.2 Specific scenario: Public spaces
Alexia, a twenty-eight-year-old woman, went to her favorite art museum to explore a new exhibition. Alexia is a designer who is very interested in art, because she thinks that art gives her good ideas that can be applied to her work. At the museum entrance, she received a brochure, which was an important piece of a new exhibition. With this brochure, she was able to tag any exhibit on display. The brochure could be folded in a way that both the front and back covers were replaced with special patterns that were recognized by computer vision technologies. Based on the position of the artwork, and the side and height that the brochure was positioned by Alexia, the artworks were tagged as objects that she either felt attracted to or found perhaps unreadable.
By the end of the exhibition, after tagging a number of objects, she found a large multi-touch table that displayed messages inviting visitors to place their brochures on it. As soon as the brochure touched the table, a group of thumbnails appeared. Those thumbnails represented the paintings she liked the most. Alexia then chose a thumbnail, which not only immediately expanded, but also displayed a text view for input of short comments. A question was also displayed asking her which kind of emotions or insights this artwork provoked on her. She felt confident that the artist dealt with gender inequality. So she typed it on a virtual keyboard on the table. After that, a series of other info boxes popped up around the image. They told specific facts about the painter. The information was related to Alexia’s comments.
Suddenly, she realized that a line crossed the multi-touch table connecting her painting to another artwork enlarged by Roger, who was also an art lover. She was curious to know what the relationship was between these objects. She then realized that a number of other thumbnails popped up on the line. Next to the thumbnails, there were some keywords that revealed more about them. Those artworks were also part of the museum collection and somehow related to Alexia’s and Roger’s objects. When she chose another favorite artwork, a new line was drawn, but this time the table created a connection to Paul’s favorite panting. Paul noticed the line coming from her artwork, and realized that an arrow appeared next to the line pointing to Alexia’s position. By swiping it into Alexia’s direction, his favorite painting traveled across the line arriving at her location. She liked Paul’s recommendation. It just gave her a new inspiration that she hoped she would find today.
5. Conclusion
In this paper, a new model was proposed to foster conversations between communities and institutions through technology. To begin with, curators construct Knowledge Maps during their research by using Module I of the Lisa Platform as an annotation tool. Afterwards, they start producing content that will serve to create exhibition catalogs or other similar materials. Module II of the Lisa Platform helps curators in this task by giving them recommendations based on the Knowledge Maps. When integrating the Lisa Platform into exhibition kiosks, visitors’ insights can be added to existing Knowledge Maps. Those insights are capable of influencing curatorial decisions, since they are also displayed for curators as recommendations during the content production process.
References
Adamic, Lada A. (1999). “The Small World Web.” In Research and Advanced Technology for Digital Libraries, 443–52. Springer. Available http://link.springer.com/chapter/10.1007/3-540-48155-9_27
Bafoutsou, Georgia, & Gregoris Mentzas. (2002). “Review and Functional Classification of Collaborative Systems.” International Journal of Information Management 22. Available http://imu.ntua.gr/sites/default/files/biblio/Papers/review-and-functional-classification-of-collaborative-systems.pdf
Baldwin, Carliss Y., & C. Jason Woodard. (2009). “The Architecture of Platforms: A Unified View.” Platforms, Markets and Innovation, 19–44.
Bassett, D. S., & E. Bullmore. (2006). “Small-World Brain Networks.” The Neuroscientist 12(6): 512–23. doi:10.1177/1073858406293182.
Berners-Lee, Tim. (1989). “Information Management: A Proposal.” March. http://www.w3.org/History/1989/proposal.html
Berners-Lee, Tim, James Hendler, Ora Lassila, et al. (2001). “The Semantic Web.” Scientific American 284(5): 28–37.
Bizer, Christian, Tom Heath, & Tim Berners-Lee. (2009). “Linked Data – the Story so Far.” International Journal on Semantic Web and Information Systems 5(3): 1–22.
Brown, Tim. (2009). Change by Design: How Design Thinking Transforms Organizations and Inspires Innovation. First edition. New York: Harper Business.
De Araújo, Leonardo Moura. (2014). “Strategies for Harnessing the Collective Intelligence of Cultural Institutions’ Communities.” In CSEDU 2014, Sixth International Conference on Computer Supported Education. Spain. Accessed December 23. Available https://files.ifi.uzh.ch/stiller/CLOSER%202014/CSEDU/CSEDU/Social%20Context%20and%20Learning%20Environments/Short%20Papers/CSEDU_2014_197_CR.pdf
Eguiluz, Victor M., Dante R. Chialvo, Guillermo A. Cecchi, Marwan Baliki, & A. Vania Apkarian. (2005). “Scale-Free Brain Functional Networks.” Physical Review Letters 94(1): 018102.
Facebook Developers. (2014). “Quickstart for Graph API.” Accessed December 22. Available https://developers.facebook.com/docs/graph-api/quickstart/v2.2
Griffiths, Dorothy, Nelson Phillips, Graham Sewell, & Joan Woodward. (2010). Technology and Organization: Essays in Honour of Joan Woodward. Bingley [u.a.]: Emerald.
Kramera, Adam D. I., Jamie E. Guillory, & Jeffrey T. Hancock. (2014). “Experimental Evidence of Massive-Scale Emotional Contagion through Social Networks.” PNAS 111(29): 10779.
Marupaka, Nagendra, Laxmi R. Iyer, & Ali A. Minai. (2012). “Connectivity and Thought: The Influence of Semantic Network Structure in a Neurodynamical Model of Thinking.” Neural Networks 32 (August): 147–58. doi:10.1016/j.neunet.2012.02.004.
Moreno-Llorena, Jaime, Claros Iván, Rafael Martín, Ruth Cobos, Juan de Lara, & Esther Guerra. (2013). “Towards a Functional Characterization of Collaborative Systems.” In Yuhua Luo (ed.). Cooperative Design, Visualization, and Engineering, 182–85. Springer. Available http://books.google.pl/books?id=-_7097fI7c4C&pg=PA182&lpg=PA182&dq=%22Towards+a+Functional+Characterization+of+Collaborative+Systems%22&source=bl&ots=oWaAEx-tjS&sig=g-MNYNh04AQKp0-rivwoSsjr_3U&hl=en&sa=X&ei=mQg3UsDLHMKshQewqIHwDg&redir_esc=y#v=onepage&q=%22Towards%20a%20Functional%20Characterization%20of%20Collaborative%20Systems%22&f=false
O’Donnell, Angela M., Donald F. Dansereau, & Richard H. Hall. (2002). “Knowledge Maps as Scaffolds for Cognitive Processing.” Educational Psychology Review 14(1): 71–86.
Page, Lawrence, Sergey Brin, Rajeev Motwani, & Terry Winograd. (1999). “The PageRank Citation Ranking: Bringing Order to the Web.” Available http://ilpubs.stanford.edu:8090/422
Rettberg, Scott. (2005). “All Together Now: Collective Knowledge, Collective Narratives, and Architectures of Participation.” Digital Arts and Culture. Available http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.103.5802&rep=rep1&type=pdf
Schilling, Melissa A. (2014). “A ‘Small-World’ Network Model of Cognitive Insight.” Creativity Research Journal 17: 177–85. Consulted December 28, 2014.
Toby, Skeggs. (2014). “Visitor Figures 2013: Exhibition & Museum Attendance Survey.” The Art Newspaper – Special Report XXIII (256): 2–3.
Watts, D. J., & S. H. Strogatz. (1998). “Collective Dynamics of ‘Small-World’ Networks.” Nature 393 (6684): 440–42.
Weber, Steven. (2000). “The Political Economy of Open Source Software.” BRIE Working Paper. Available http://escholarship.org/uc/item/3hq916dc.pdf
Wikipedia. (2015). “Wikipedia, the Free Encyclopedia.” Homepage. Consulted February 27, 2015. Available http://en.wikipedia.org/wiki/Wikipedia.
Cite as:
. "Beyond browsing and searching: Design and development of a platform for supporting curatorial research and content creation." MW2015: Museums and the Web 2015. Published January 15, 2015. Consulted .
https://mw2015.museumsandtheweb.com/paper/beyond-browsing-and-searching-design-and-development-of-a-platform-for-supporting-curatorial-research-and-content-creation/